
OpenCV与经典视觉算法
本博客参考《OpenCV3编程入门》(毛星云 冷雪飞 电子工业出版社)写成(还有来自毛星云dalao在csdn写成的系列博文),本篇内容旨在总结嵌入式设备中常用(基础)的机器视觉算法(上面书籍的前七章),代码主要使用OpenCV实现,部分代码可以直接在OpenMV或类似的嵌入式平台上部署
悼念浅默大佬,感谢他为我们带来的技术博客和教程
配环境与hello world代码
这里没有使用原教程的VS环境,而是使用VSCode、MinGW、CMake、OpenCV源码搭建了一套通用的开发环境
注意:这是在Windows下进行搭建,Linux下的环境配置要简单很多
步骤如下:
下载所有需要的软件(这里的OpenCV使用4.5.0版本)
MinGW用于编译C/C++程序,因为VSCode仅仅是一个代码编辑器,没有办法独立完成编译工作。使用VSCode+gcc的一个优点就是可以避免像VS那样生成一大堆文件,而且这一套配置可以跨平台操作,Linux和Windows都可以用相似的环境完成OpenCV开发;缺点在于它的性能没有VS那么好,不过对于学习来说已经足够了
编译OpenCV源码
先使用CMake-gui在源码目录下进行构建,生成Makefile
点击
Configure弹出以下窗口,如下配置即可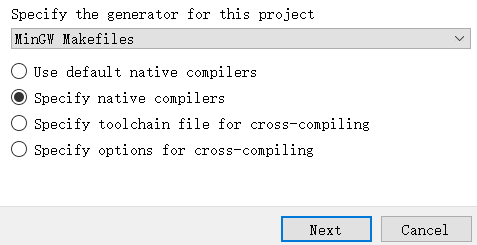
下个窗口选择要使用的MinGW编译器,分别用gcc和g++编译C和C++
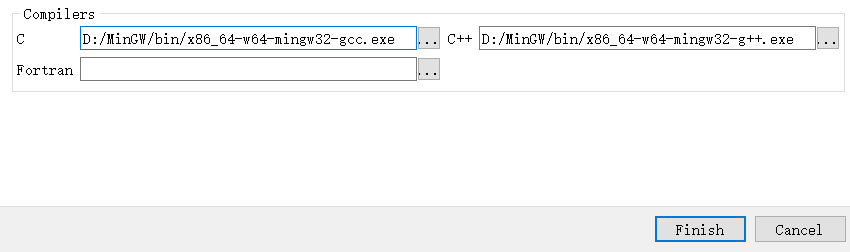
完成配置后就让他自己构建,会花一段时间(视电脑CPU性能定,6核12线程一般十几分钟就能跑完了)
注意在构建时一定要联网,因为CMake会从网上下载一些依赖包
很多错误都是由于依赖包连不上、下不完导致的
中间可能会出现红色的报错,如果最后结果里面是configuring done就可以忽略;如果执行时中断,则存在其他问题。构建完毕后,在上面的选项框里勾选BUILD_opencv_world、WITH_OPENGL、BUILD_EXAMPLES,确保不勾选WITH_IPP、WITH_MSMF、ENABLE_PRECOMPILED_HEADERS,并且CPU_DISPATCH选空。再点击一次configure,最后结果如下:
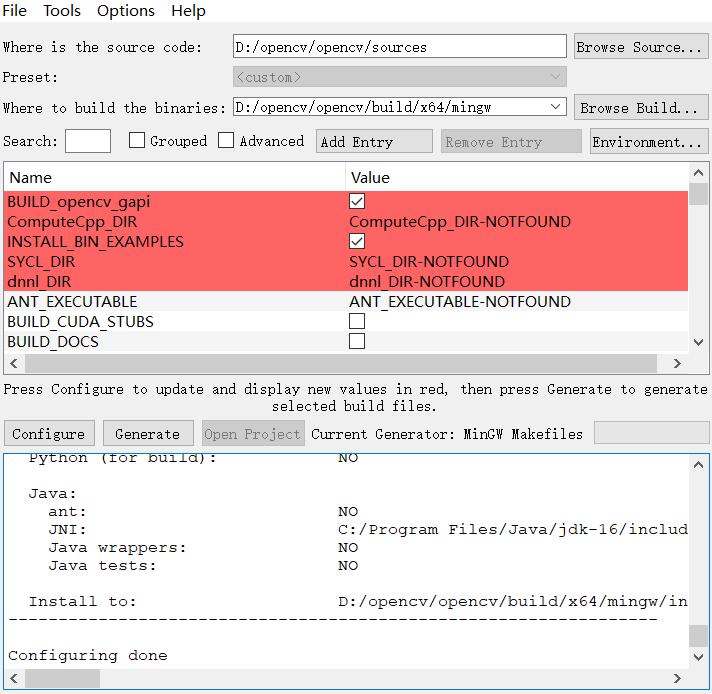
随后点击Generate,正常的话会显示非红色的消息Generate Done

这样Makefile就建好了。可以切换到目录
${opencv根目录}\build\x64\mingw看看,会发现有一个Makefile。随后就可以进行编译啦!使用CMD切换到MakeFile所在目录,执行minGW32-make命令使用多线程编译命令minGW32-make -j <这里写需要使用的CPU核心数>,个人建议第一次编译使用单线程,因为多线程编译虽然很快但是不会弹出报错信息,容易反复编译错而找不到bug所在编译源码出错,重新构建
根据笔者的经验,大多数编译源码的时候会出错,所以这时候就要重新构建,去掉一些出错的部分,或者下载新版本源码,抑或是苦逼查错
笔者编译时遇到了以下错误
In file included from D:\opencv\opencv\sources\3rdparty\openexr\IlmImf\ImfAttribute.cpp:44:
D:/opencv/opencv/sources/3rdparty/openexr/IlmThread/IlmThreadMutex.h:131:20: error: ‘mutex’ in namespace ‘std’ does not name a type
using Mutex = std::mutex;大意是缺少mutex
凭借经验知道mutex是pthread库里面的东西,按理说不应该缺少,百度/Google/StackOverflow一下发现是MinGW-W64的问题,重下新版本,然后重新配置


[ 65% ] Building RC object modules/world/CMakeFiles/opencv_world.dir/vs_version.rc.obj
gcc: error: long: No such file or directory
mingw32-make[2]: *** [modules\world\CMakeFiles\opencv_world.dir\build.make:11240: modules/world/CMakeFiles/opencv_world.dir/vs_version.rc.obj] Error 1
这是个make的经典错误,No such file or directory基本上就是.obj文件没有生成,这时候就只能查看CMake原来的指令再手动编译一遍vs_version.rc这个文件了
发现上面黑体标出的部分是CMake文档中出错的指令,依照他找到原指令位于modules\world\CMakeFiles\opencv_world.dir\build.make的11240行,可以直接打开文件,搜索vs_version.rc
1
2
3
4modules/world/CMakeFiles/opencv_world.dir/vs_version.rc.obj: modules/world/vs_version.rc
@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --green --progress-dir=D:\opencv\opencv\build\x64\mingw\CMakeFiles --progress-num=$(CMAKE_PROGRESS_491) "Building RC object modules/world/CMakeFiles/opencv_world.dir/vs_version.rc.obj"
cd /d D:\opencv\opencv\build\x64\mingw\modules\world && D:\mingw64-posix-seh\bin\windres.exe -O coff $(RC_DEFINES) $(RC_INCLUDES) $(RC_FLAGS) D:\opencv\opencv\build\x64\mingw\modules\world\vs_version.rc CMakeFiles\opencv_world.dir\vs_version.rc.obj发现里面的指令为
1
2
3cd /d D:\opencv\opencv\build\x64\mingw\modules\world
D:\mingw64-posix-seh\bin\windres.exe -O coff D:\opencv\opencv\build\x64\mingw\modules\world\vs_version.rc CMakeFiles\opencv_world.dir\vs_version.rc.obj切换到build目录后照样执行,发现编译成功
重新
minGW32-make,bug解决解决所有bug后,发现编译成功
生成完整的OpenCV库
在编译目录下使用指令
minGW32-make install即可将所有生成的文件整理并安装到install目录,将这个目录下的x64/mingw/bin子目录加入环境变量Path,这就让生成的动态链接库可以被调用在
x64\mingw\samples子目录下保存了所有示例程序的编译结果在
etc子目录下保存了常用的模型配置VSCode
在VSCode里面安装C/C++插件,配置好三个文件后就可以按照VS的方式对OpenCV代码进行编译调试了
分别是
用于配置环境的
c_cpp_properties.json1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23{
"configurations": [
{
"name": "Win32",
"includePath": [
"${workspaceFolder}/**",
"D:/opencv/opencv/build/x64/mingw/install/include",
"D:/opencv/opencv/build/x64/mingw/install/include/opencv2"
],
// "defines": [
// "_DEBUG",
// "UNICODE",
// "_UNICODE"
// ],
"defines":[],
"compilerPath": "D:/mingw64-posix-seh/bin/g++.exe",
"cStandard": "c11",
"cppStandard": "c++17",
"intelliSenseMode": "${default}"
}
],
"version": 4
}用于生成调试的
launch.json1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31{
"version": "0.2.0",
"configurations": [
{
"name": "opencv4.5.0 debug",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/${fileBasenameNoExtension}.exe",
"args": [
// "/C",
// "${fileDirname}/${fileBasenameNoExtension}.exe",
// "&",
// "pause"
],
"stopAtEntry": false, //这里如果为false,则说明调试直接运行(反之则会在编译完之后停止)
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": true, //是否调用外部cmd
"MIMode": "gdb",
"miDebuggerPath": "D:/mingw64-posix-seh/bin/gdb.exe", //自己针对要用的调试器进行设置
"preLaunchTask": "opencv4.5.0 compile task", //在调试之前先进行编译任务
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": false
}
]
}
]
}用于生成任务的
tasks.json1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "opencv4.5.0 compile task",
"type": "shell",
"command": "D:\\mingw64-posix-seh\\bin\\g++.exe",
"args": [
"${file}",
"-o",
"${workspaceFolder}\\${fileBasenameNoExtension}.exe",
"D:\\opencv\\opencv\\build\\x64\\mingw\\install\\x64\\mingw\\bin\\libopencv_world450.dll",
"-I",
"D:\\opencv\\opencv\\build\\x64\\mingw\\install\\include",
"-I",
"D:\\opencv\\opencv\\build\\x64\\mingw\\install\\include\\opencv2",
"-g"
],
"options": {
"cwd": "D:\\mingw64-posix-seh\\bin"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}配置完以后使用
F5键就可以直接编译运行调试了测试
使用以下代码进行图片读取-显示测试
1
2
3
4
5
6
7
8
9
10
11
12
using namespace cv;
int main()
{
Mat img=imread("test.jpg");
imshow("image",img);
waitKey();
return 0;
}
OpenCV入门
基本函数
1 | imread("文件名"); //读取图像 |
Mat类
Mat类是OpenCV用于图像的基本数据结构,由矩阵头和矩阵指针组成。矩阵头中包含了矩阵尺寸、存储方法、存储地址等信息;矩阵指针指向存储所有像素值的矩阵,矩阵的维数由图像的存储方法决定。矩阵头长度恒定,但矩阵本身的尺寸会依图像的不同而不同,且通常比矩阵头的尺寸大数个数量级。
OpenCV支持Mat对象的显式创建和格式化输出
OpenCV使用引用计数机制来提高运行效率:每个Mat对象有自己的信息头但共享同一个矩阵——相同图像的矩阵指针可以指向同一个地址,在拷贝构造函数过程中只复制信息头和矩阵指针,从而避免了复制矩阵的大开销。
以下代码中的A,B,C三个Mat对象都指向内存中同一个数据矩阵
1 | Mat A,C; |
OpenCV还通过这个机制实现了内存的自动管理,C++、Python接口中都不需要考虑内存释放问题
如果需要复制图像的矩阵,应该使用clone()或copyTo()函数
信息头还具有特殊用法:可以创建包含边界信息的信息头来划分感兴趣区域(ROI)
1 | Mat ROI(A,Rect(p_1,p_2,p_3,p_4)); //通过矩形的四个端点创建ROI |
划分ROI是CV中常用于简化算法的思路,后面还会再提到
像素值通过指定色彩空间和数据类型来存储为数字格式。色彩空间是指针对一个给定的颜色,如何组合颜色元素来对其编码。最简单的颜色空间是灰度空间(GRAY),它只处理黑色和白色,对两种颜色进行组合就可以得到不同程度的灰色。使用灰度空间可以很好地发现图像的深度特征。RGB色彩空间是最常见的,通过组合红(Red)、绿(Green)、蓝(Blue)三原色,可以产生所有其他颜色,有时为了表示透明度也会加入Alpha元素。HSV和HLS色彩空间把颜色分解成色调、饱和度和亮度/明度。YCrCb(即YUV)在JPEG图像中常见,主要用于优化彩色视频信号的传输,它最大的优点在于只需占用极少的带宽即可表示与RGB色彩空间一样的图像。Y表示明亮度;U和V表示色度,其中U(也就是Cr)反映RGB输入信号红色部分与RGB信号亮度值之间的差异。而V(即Cb)反映的是RGB输入信号蓝色部分与RGB信号亮度值之间的差异。OpenCV有函数可以将图片在各个色彩空间中进行转换。图片中每个组成元素都有自己的定义域,定义域取决于其数据类型。最小的数据类型是char,可以表示1600万种可能的颜色(RGB色彩空间);使用float或double可以获得更精细的颜色分辨能力,随着元素尺寸增大,图像所占内存也会增大。
计算机中的图片通过像素表示,每个像素对应一个数值,分辨率为640*480的图片,就有307200个像素点,每个像素点都有自己的数值,比如RGB空间中一个三通道的值(0,0,255)表示红色的像素点,整张图片可以用一个二维数组(矩阵)表示,其中的一个像素就是二维数组中的一个元素。色彩空间决定了其编码方式,数据类型决定了其精度
1 | unsigned char image[480][640]; |
Mat类就是通过调用这样的矩阵实现图像存储功能的,因此从底层出发可以发现Mat对象能够实现矩阵功能。
将图像矩阵中表示颜色的值称为通道(Channel),灰度图像是单通道的:一个坐标位置有一个灰度值;RGB图像是三通道的:一个坐标位置有R、G、B三个正交(互不相干)的色彩值。
事实上,OpenCV中将RGB图像按照通道B-G-R的顺序保存
OpenCV提供了三种方法访问每个像素的数据,分别是:
- 指针访问:通过对Mat对象使用
[]操作符,面向过程的思路,直接访问Mat对象底层的矩阵数据,速度最快 - 迭代器
iterator:STL的经典用法,获得图像矩阵的begin、end,再增加迭代知道从begin到end,使用*操作符就可以访问到具体数据了,这种方法稍慢,但更加安全,不会发生指针越界 - 动态地址计算:该方法最慢,但是很直观,使用Mat对象的成员函数
at(x,y)来存取图像元素
其他常用数据结构
Point类:表示点
1
2
3
4Point point;
point.x = 10;
point.y = 5;
Point p = Point(3,4);Scalar类:表示颜色
Scalar()表示具有4个元素的数组,常常用于传递像素值。特别地,如果只写三个参数进行初始化或赋值,OpenCV会视为三元素数组,也就是说第四个元素只有在用到时才需要写出来1
2Scalar(r,g,b,a);
Scalar(r,g,b);Size类:表示尺寸或大小
这是一个对
Size模板类在Size_<int>下的封装,常用以下表达式表示某个尺寸(宽x高)1
2
3
4
5Size body;
body.width;
body.height;
Size(3,4); //宽3 高5Rect类:表示矩形
这个类的成员变量有
1
2
3
4x; //左上角点的坐标x
y; //左上角点的坐标y
width; //矩形宽度
height; //矩形高度它有以下几个基本成员函数
1
2
3
4
5
6
7
8
9
10
11Size(); //返回长和宽
area(); //返回面积
contains(Points); //判断点是否在矩形内
inside(Rect); //判断矩形是否在矩形内
tl(); //返回左上点坐标
br(); //返回右下点坐标
Rect rect = rect_1 & rect_2; //求矩形交集
Rect rect = rect_1 | rect_2; //求矩形并集
Rect rect_shift = rect + point; //平移
Rect rect_scale = rect + size; //缩放
绘制基本图形
- 直线
- 椭圆
- 圆
- 矩形
- 填充多边形
参考下面的示例程序即可
1 |
|
ROI
当我们对一个图像进行处理时,常常会因为硬件限制无法对全部像素进行运算,这时候就可以考虑使用ROI分割。ROI即感兴趣区域,分割我们感兴趣的图像区域进行针对性计算。这个方法分为两个维度:色彩空间中的ROI和图像尺寸中的ROI
在色彩空间中取ROI即颜色空间缩减(Color Space Reduction):将现有色彩空间值除以某个输入值(取整),可以获得较少的颜色数
这个算法的特点是缩减运算量,同时会缩减得到的信息准确度(图像色彩变模糊了)
比如颜色0到9统一取为0,10到9统一取为10……
可以直接使用uchar定义域内的颜色缩减运算
$$
I_{new}=\frac{I_{old}}{10} \times 10
$$
这样就能通过uchar除以int值来获得新的char值(向下取整),进而缩减颜色空间,得到ROI
为了进一步简化运算,常常将某个色彩空间的对应缩减值计算好以后存在一个查找表(LUT)中,生成新图像的时候采用以下算法:
- 遍历图像矩阵的每个像素
- 对像素应用上述公式或查表得到结果
可以使用加减赋值运算对上面的乘除运算进行简化,而OpenCV推荐使用查找表函数LUT(),通过以下代码进行处理
1 | Mat look_up_table(1,256,CV_8U); //以256位颜色空间为例 |
图像尺寸上的ROI就是之前介绍过的狭义上的ROI:从图像中选择一个区域以进行进一步处理,能够减少处理时间、增加精度
一般是圈定一个矩形区域或指定感兴趣行或列的范围来定义ROI。
前一种方法使用以下语句实现
1 | Mat img; |
后一种方式使用以下语句实现
1 | ROI = img(Range(a,a+logo.rows),Range(b,b+logo.cols)); |
ROI的一个常见用法就是进行图像叠加(下面的示例是原文示例)
1 | /* 通过一个图像掩膜mask就可以将插入部分的像素设置为掩膜图像的像素 */ |
图像处理的基本方法
作为图像叠加的扩展操作,线性混合操作是图像处理中典型的二元像素操作,它遵循以下公式
$$
g(x)=(1-a)f_a(x)+af_3(x)
$$
a是范围在0到1之间的alpha通道值,可以对两个图片实现时间上的交叉溶解效果,也就是前一图片缓慢消失,后一图片缓慢出现,opencv中使用addWeighted()函数进行处理
1 | //计算两个数组(图像)的加权和 |
可以参考下面的示例使用该函数
1 |
|

可以看到右边的图片就是左侧图片叠加了一个rain.jpg而成
通道分离与通道混合也是两个常用的图像操作,它们分别将一个多通道数组分离成多个单通道数组和将多个单通道数组合并成一个多通道数组
split函数可进行通道分离,执行如下算法:
$$
mvc=src(I)_c
$$
典型代码如下:
1 | vector<Mat> channels; |
merge函数是它的逆向操作,可以组合一些给定的单通道数组,将他们合并成一个多通道数组
典型实现如下:
1 | vector<Mat> channels; |
经典CV算法
定义图像处理算子:算子是一个函数,接收一个或多个输入图像,并产生输出图像
算子的概念等价量子力学中引入的算符,只不过算子单纯对张量进行运算,操作数不一定具有物理意义,而算符要求变换后的张量具有一定物理意义
算子/算符都描述了从一个函数空间(如巴拿赫空间和希尔伯特空间)到另一个函数空间的映射。算子有线性与非线性之分,矩阵是最常见的线性算子。一个函数可以被视为一个向量,算子作用在函数上的过程就是对函数对应的向量做线性变换的过程。
一个算子总可以表示为:
$$
g(x)=h(f(x)) \leftrightarrow g(x)=h(f_0(x) \cdots f_n(x))
$$
最简单的图像处理变换算子是点操作(pointoperators)算子,仅仅根据输入像素值(有时会加入某些全局信息或参数)来计算相应的输出像素值,可以实现包括亮度和对比度调整、颜色校正和变换。对于点算子,可以通过乘上一个常数来实现对比度调节,通过加上一个常数实现亮度值的调节
$$
g(i,j)=a*f(i,j)+b
$$
式中a表示增益,控制图像的对比度;b表示偏置,用来控制图像的亮度;式中i、j代表像素位置
使用下面的函数来调整对比度
1 | //在三个for循环内执行运算 g_dstImage(i,j) = a*g_srcImage(i,j) + b |
三个循环里面,最外层是遍历图像行,中层遍历图像列,最内层是遍历三个通道;使用saturate_cast函数对结果进行转换,防止运算结果超出像素取值范围,确保它是有效值
离散傅里叶变换
离散傅里叶变换(Discrete Fourier Transform,DFT)是指傅里叶变换在 时域和频域都呈现离散的形式,将时序信号的采样变换为在离散时间傅里叶变换频域(DTFT)的采样。对有限长的离散信号做DFT,也需要对其经过周期延拓成为周期信号以后在进行变换。实际应用中,常使用快速傅里叶变换(FFT)计算DFT
二维图像的傅里叶变换可表示为
$$
F(k,l)=\sum_{i=0}^{N-1} \sum_{j=0}^{N-1} f(i,j)e^{-i2\pi (\frac{ki}{N}+\frac{lj}{N})}
$$
其中f是空间域值,F是频域值,傅里叶变换作用在原图像后需要使用实数图像+虚数图像表示原图像,或者用幅度图像+相位图像的形式表示原图像。频域空间中,图像的高频部分代表了图像的细节、纹理信息,低频部分代表了图像的轮廓信息。可以通过滤波器来处理图像噪声,让某个特定频率范围内的噪声被去除,从而恢复原图。图像增强与去噪、图像边缘检测、图像特征提取、图像压缩等算法都可以靠DFT完成
opencv提供了dft()函数对一维或二维浮点数数组进行正向或反向DFT
1 | void dft( |
如果nonzeroRows参数为非零值,函数会假设只有输入矩阵的第一个非零行非零元素,或只有输出矩阵的第一个非零行非零元素,这样可以对其他行进行更高效的处理
OpenCV围绕DFT给出了一系列函数,如果需要可以自行查看OpenCV源码和其中的注释
线性滤波
图像处理领域中,在尽量保证图像细节特征的条件下对目标图像噪声进行抑制的过程称为滤波。比较常见的滤波就是平滑滤波,也称为平滑处理:图像的能量大部分集中在幅度谱的低频和中频段,而高频段大部分有效数据都会被噪声淹没。通过一个低通滤波器,将高频信号全部过滤就能起到减弱噪声的影响,不过也一定会降低部分有效信息。不难得出图像滤波的目的:
- 抽出对象的特征作为图像识别的特征模式
- 消除图像数字化时所混入的噪声
针对这两个目标可以得到滤波处理的要求:
- 信号损失小:不能损坏图像轮廓和边缘等重要信息
- 噪声抑制程度高:使图像清晰,视觉效果好
很多情况下平滑滤波都用于将图像进行模糊处理;在另外一些情况下, 滤波可以让图像中的噪音消除。
下面是使用方框滤波对图像进行处理的例子,可以看出,右图中虽然图像明显模糊不清,但是图像的边沿、色块分布都得到了保留;
后面的示例图片都是圆神了OvO
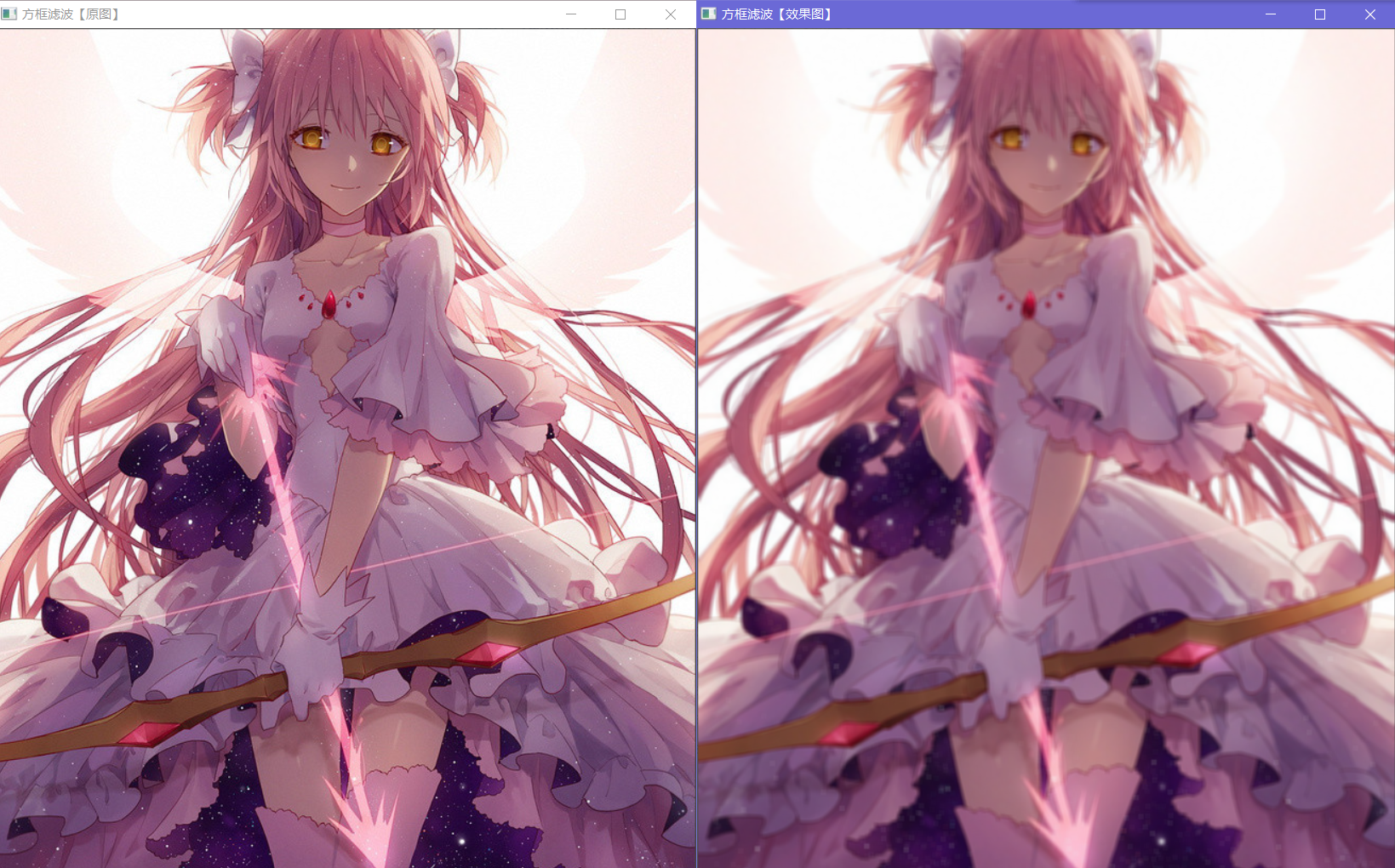
而作为“噪声”的一些斑点(比如左下角的“星空”)会被滤除
 可以对比一下两张图
可以对比一下两张图
左图中白色斑点被滤去——在本图中这些信息是作为有效信息出现的;但是反过来,这样的滤波过程可以将部分影像中出现的“雪花点”干扰滤除,让我们得到相对更清晰的图像
对于滤波器,我们可以将它看成一个包含加权系数的窗口,使用这个滤波器处理图像时就将窗口放到图像上,透过窗口来看得到的图像。最常见的线性滤波器,顾名思义,是使用线性运算的滤波过程,和信号与系统中的传统滤波器类似,可以分成低通、高通等不同频率的滤波器
滤波过程通常使用卷积操作来实现。这个卷积和电路中常见的卷积类似但不太相同——它是将一个核函数在图像上以固定的步长滑动,同时对图像对应数据进行运算。
如果之前看过图像卷积的科普,可能会比较直观地了解到卷积=互相关=邻域滤波,补充资料可以查看
笔者在神经网络基础概念中提到卷积神经网络中卷积的部分
线性滤波过程可以用如下公式描述:
$$
g(i,j)=\sum_{k,I}f(i+k,j+I)h(k,I)
$$
其中h就是核函数,如果在图像中往往使用一个矩阵表示
上式可以简写为
$$
g=f \otimes h
$$
g表示输出像素值,f表示输入像素值。这个运算是矩阵的运算,而构成它基本结构的只是乘加运算,所以是符合线性条件的,因此就被称线性滤波
线性滤波包含:
方框滤波:使用如下矩阵作为核


normalize指的是使用归一化,当且仅当使用归一化时,方框滤波会变为均值滤波
均值滤波:取核窗口内对应原图所有像素的平均值作为这一块区域的像素值
均值滤波不能很好地保护图像细节,会让图像变得模糊而无法去除噪声点
高斯滤波:使用正态分布函数(高斯函数)与图像卷积的滤波,也就是将高斯函数作为核函数
效率不是最高的,但是比较常用,可以很好得抑制服从正态分布的噪声
$$
G_0(x,y)=Ae\frac{-(x-u_x)^2}{2\sigma^2_x} +\frac{-(y-u_y)^2}{2\sigma^2_x}
$$
三者在OpenCV中的对应函数如下
1 | void cv::boxFilter(cv::InputArray src, //输入 |
非线性滤波
在很多情况下,适用邻域像素的非线性滤波可以得到更好的效果——线性滤波具有线性性质,易从频率响应角度进行分析;而非线性滤波可以处理实际问题中的非线性因素(比如噪声往往是散粒噪声(比如上面示例中提到的“雪花点”)而不是高斯噪声)
比较典型的线性滤波算法包括:
中值滤波:使用像素点邻域灰度值的中值来代替对应像素点的灰度值
该算法常用于处理脉冲噪声、椒盐噪声等,同时在一定条件下可以克服常见线性滤波器带来的图像细节模糊,常用于保护边缘信息;但是对一些具有较多细、尖顶特征的图像不适用
但是存在性能开销大的问题,中值滤波比均值滤波处理相同量的数据要多花5倍以上时间
双边滤波:在高斯滤波函数基础上增加了一个高斯方差sigma-d,这是基于空间分布的高斯滤波函数,从而能让边缘附近离得较远的像素不会对边缘上的像素值影响过多,从而保证了边缘特征
同时考虑空域信息和灰度相似性的滤波,可以实现边缘保存(edge preserving);不过由于保存了很多高频信息所以对彩色图像里的高频噪声不能实现有效滤除,只能对低频信息进行较好的滤波
输出像素值依赖于邻域像素值的加权组合
$$
g(i,j)=\frac{\sum_{k,l}f(k,l)\omega (i,j,k,l)}{\sum_{k,l}\omega (i,j,k,l)}
$$
其中$\omega$是加权系数,由定义域核d和值域核r共同决定
$$
d(i,j,k,l)=exp(-\frac{(i-k)^2 +(j-l)^2}{2\sigma^2_d}) \newline
r(i,j,k,l)=exp(-\frac{||f(i,j)-f(k,l)||^2}{2\sigma^2_r}) \newline
\omega(i,j,k,l)=d(i,j,k,l) * r(i,j,k,l)
$$
二者的OpenCV实现如下:
1 | void cv::medianBlur(cv::InputArray src, |

可见双边滤波的模糊效果就不那么强了,仔细看可以发现很多光点都被滤除了;而中值滤波的效果就好像是把图像变成了一个个色块,边缘清晰但是图片的内部细节就看不到啦

形态学滤波——膨胀和腐蚀
数学形态学是一门建立在格论核拓扑学基础之上的图像分析学科,是数学形态学图像处理的基本理论,其中的基本运算包括二值腐蚀和膨胀、二值开闭运算等。简单来说,形态学操作就是基于形状的一系列图像处理操作。
OpenCV提供了膨胀和腐蚀功能函数
膨胀和腐蚀可以实现消除噪声、分割出独立的图像元素、寻找图像中的明显的极大值区域或极小值区域、求出图像梯度这些功能。
需要注意:膨胀和腐蚀都是对图像的高亮部分(白色)而言的,膨胀是指让图像中的高亮部分扩大;腐蚀则是指图像中的高亮部分缩小
膨胀本质上是求局部最大值,一般通过将图像和核进行卷积来实现——核可以是任何形状和大小,它拥有一个单独定义出来的参考点,我们将其称为锚点(anchor point),在膨胀操作中,这个核会与图像卷积然后计算覆盖区域中像素点的最大值,将这个最大值赋值给锚点对应的原图像像素,从而实现高亮区域增长的效果
腐蚀则是将核范围内的最小值赋值给锚点对应的原图像像素,从而实现高亮区域缩小
OpenCV提供的API如下所示
1 | void cv::erode(cv::InputArray src, |
膨胀和腐蚀的结果如下:


什么阴间特效
圆神我的圆神/(ㄒoㄒ)/~~
使用基本的形态学运算就可以实现一些比较复杂的图像处理算法了,比如基于传统算法的字符分割,虽然只能处理正对着的数字,但是可以适用于很多工业领域,在图片的预处理中就用到了膨胀和腐蚀来去除图像中的背景干扰
python实现如下
1 | import cv2 |
可以将图片变为以下效果

可以看到图像上的噪点都被滤去了
上面使用到的二值化函数会在之后提到
形态学滤波——开闭运算
OpenCV提供了一个利用腐蚀和膨胀两种基本操作实现更复杂形态学滤波算法的函数
1 | void cv::morphologyEx(cv::InputArray src, |
这个函数可以根据不同的标识符对图像进行不同处理,几个常用的算法如下:
开运算(Open Operation):先腐蚀后膨胀。常用于消除小物体或小亮点,可以在平滑较大物体边界的同时不明显改变其面积
上面的图像处理示例就运用了开运算,只不过使用了两个分立的函数
1
MORPH_OPEN
闭运算(Closing Operation):先膨胀后腐蚀。常用于排除小的黑色区域或噪声点
1
MORPH_CLOSE
形态学梯度(Morphological Gradient):膨胀图-腐蚀图。可以将团块(blob)的边缘突出出来,从而保留物体的边缘特征
注意:形态学梯度运算和后面要说的边缘检测完全不一样,不过达到的效果确实比较类似
1
MORPH_GRADIENT
顶帽(Top Hat):又称为“礼帽”运算,是原图像和开运算的效果图之差。开运算常用于放大裂缝或者局部低亮度,于是顶帽运算就可以分离比临近点亮一些的团块,在图像前景图是小物体且背景占比较大的情况下可以使用这个算法进行背景提取
1
MORPH_TOPHAT
黑帽(Black Hat):闭运算的结果图和原图像之差。常用于突出暗色团块,从而能让轮廓被分离出来
1
MORPH_BLACKHAT
使用MORPH_EROADE和MORPH_DILATE参数可以控制上面的函数实现腐蚀、膨胀效果
漫水填充
漫水填充(Flood Fill)是另一个常用的算法。用特定的颜色填充连通区域,常用于标记或分离图像的一部分,从而对其进行进一步处理或分析
注意,是漫水填充不是水漫填充——其实我一直是叫错了的,看到dalao的书以后才改过来(
漫水填充的基本实现方法就是自动选中和种子点(起始点)连通的区域,再将这一区域替换成指定的颜色,就像PhotoShop中的魔术棒功能那样——不过水漫填充查找的是和种子点连通的颜色相同的点,而魔术棒选择的是与种子点相近颜色的点,同时将这些点压进栈作为新种子。OpenCV提供了以下函数实现漫水填充
1 | int cv::floodFill(cv::InputOutputArray image, //输入图像,可以输入/输出1通道或3通道,8位或浮点图像 |
其中操作标识符有三个部分
- 低8位:控制算法的连通性,可取4(48b0000_0100)或8(8’b0000_1000),如果设置为4,则填充算法只考虑当前像素水平、垂直方向的相邻点;如果设置为8则还会考虑对角线方向的相邻点
- 高8位:可以设置为以下两种标识符的组合
- FLOODFILL_FIXED_RANGE:如果设置则会考虑当前像素与种子像素之间的差,否则会考虑当前像素与相邻像素的差
- FLOODFILL_MASK_ONLY:如果设置则不会去填充原始图像,而是会去填充掩膜图像,掩膜图像只会对重载版本的函数生效
- 中间8位:这里用于指定填充掩膜图像的值,但如果这部分的值是0,则会用1填充掩膜
所有flag可以用|连接起来,从而设置对应部分的值
图像尺寸缩放
OpenCV提供了两种方法进行图像大小缩放
resize()函数:由imgproc模块的Geometric Image Transformation子模块提供的图像缩放函数1
2
3
4
5
6
7void cv::resize(cv::InputArray src, //源图像
cv::OutputArray dst, //目标图像
cv::Size dsize, //输出图像的大小
double fx = (0.0), //沿水平轴x的缩放系数,当其等于0时,使用dsize.width/src.cols计算
double fy = (0.0), //沿水平轴y的缩放系数,当其等于0时,使用dsize.height/src.rows计算
int interpolation = 1 //指定插值方式
);需要注意:如果dsize=0,那么使用
dsize=Size(round(fx*src.cols),round(fy*src.rows))计算interpolation可用的参数有
- INTER_NEAREST:最近邻插值
- INTER_LINEAR:线性插值,常用于放大图像插值,速度较快,效率高
- INTER_AREA:区域插值,常用于缩小图像插值
- INTER_CUBIC:三次样条插值,常用于放大图像插值,速度较慢,效率低,但是比较精准
- INTER_LANCZOS4:Lanczos插值
pyrUp()和pyrDown()函数:由improc模块的Image Filtering子模块提供。
图像金字塔是图像多尺度表达的一中,主要用于图像分割,是一种用多分辨率来解释图像的有效结构。一幅图像的“金字塔”就如同真正的金字塔那样排列,分辨率逐步降低且来源于同一张原始图——每一幅金字塔图都由原图通过梯次向下采样获得,其最低部是图像的高分辨率表示,而顶部则是图像的低分辨率近似
常见的图像金字塔有
- 高斯金字塔:用于向下采样,很常见
- 拉普拉斯金字塔:用于从金字塔低层图像重建上层未采样图像,可用于预测残差,配合高斯金字塔同时使用
要从金字塔第i层生成第i+1层,需要先使用高斯核对第i层图像卷积,删除所有偶数行和偶数列,这样就能得到四分之一的图像,如此迭代操作就可以构建上层的所有金字塔。
图像向金字塔上层移动,尺寸和分辨率都会降低
OpenCV使用pryDown生成下一级金字塔;而pryUp可以将现有图像所有维度都放大两倍。
需要注意,向上采样和向下采样与金字塔方向相反——向上图像尺寸加倍,向下图像尺寸减半;同时pryUp和pryDown不是互逆的,pryUp的过程中,图像会首先在每个维度上扩大为原来的两倍,新增的行列以0填充,然后使用指定的滤波器进行卷积,从而计算出“丢失像素”的值;pryDown则会让原来的图像信息丢失,需要使用拉普拉斯金字塔辅助来获取丢失的信息
拉普拉斯金字塔定义式如下:
$$
L_i=G_i-UP(G_{i+1}) \otimes g_{5 \times 5}
$$
其中Gi表示第i层图像,UP()操作会将原图像位置位(x,y)位置的像素映射到目标图像(2x+1,2y+1)的位置随后会与5*5的高斯核进行卷积
拉普拉斯运算中的UP()在OpenCV中使用pryUp实现
拉普拉斯金字塔运算才是高斯金字塔的逆运算
1 | void cv::pyrUp(cv::InputArray src, |
需要注意,其中的Size要满足以下条件
$$
|dstsize.width - src.cols *2|\le (destsize.width \ \ mod2) \newline
|dstsize.height - src.rows *2|\le (destsize.height \ \ mod2)
$$
二值化(阈值化)
阈值化是最简单的图像分割方法,它选取一个阈值,然后将图像中的每个像素点对应灰度值与阈值进行比较,从而分隔出大于阈值和小于阈值的两个部分,OpenCV给出了两个函数完成阈值分割
1 | double cv::threshold(cv::InputArray src, |
固定阈值分割就是上面讲述的二值化过程
其中type参数有如下选项
THRESH_BINARY:二进制阈值,小于阈值的像素点被划分为0,大于阈值的点被划分为最大值maxval
这个最大值由参数maxval决定,下面同理
THRESH_BINARY_INV:反二进制阈值,大于阈值的像素点被划分为0,小于阈值的点被划分为最大值maxval
THRESH_TRUNC:截断阈值,把大于阈值的像素点赋值为阈值thresh,也就是“削去波峰”
THRESH_TOZERO:反阈值化为0,把大于阈值的像素点赋值为0
THRESH_TOZERO_INV:阈值化为0,把小于阈值的像素点赋值为0
自适应阈值分割会根据thresholdType的选择不同使用自适应阈值进行二值化
thresholdType可选:
- THRESH_BINARY:将大于阈值的像素点设置为最大值,其他点设为0
- THRESH_BINARY_INV:小于等于阈值的像素点设置为最大值,其他点设为0
阈值会根据adaptiveMethod参数设置而自动计算,这个参数可选
- ADAPTIVE_THRESH_MEAN_C:阈值=(blockSize * blockSize邻域内(x,y) - C 的平均值)
- ADAPTIVE_THRESH_GAUSSIAN_C:阈值=(blockSize * blockSize邻域内(x,y) - C)与高斯窗交叉相关(卷积)后的加权总和
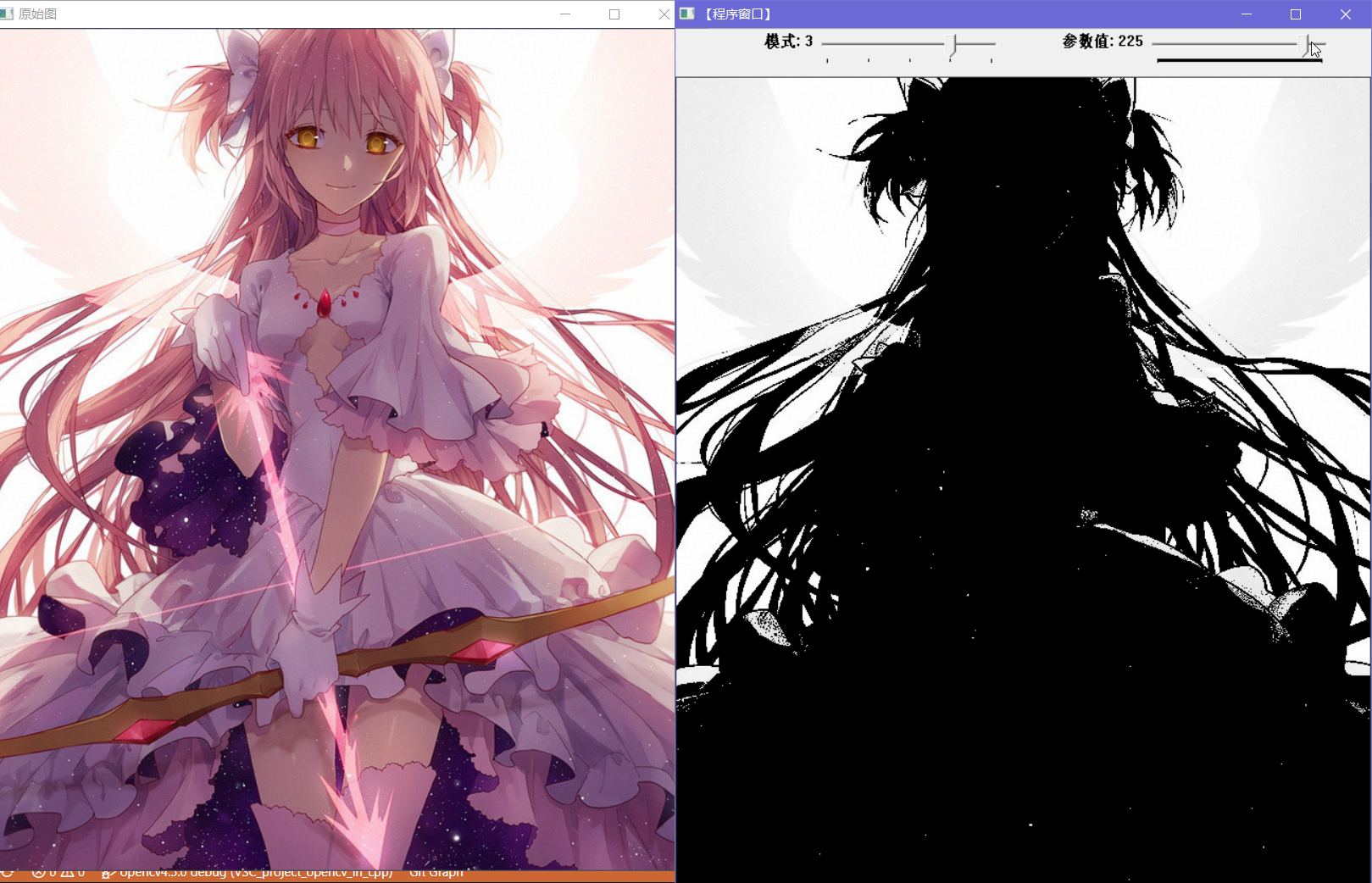
观察给出的示例,可以发现成功把深色的范围给筛选出来了
在之前给到的图像例子中,出现了二值化的代码
1 | _, image = cv2.threshold(image, 50, 255, cv2.THRESH_BINARY) # 二值化 |
这里就使用了threshold函数的基本二值化功能
边缘检测
边缘检测就是把图像的边缘信息提取出来,用数学角度看,就是找到图像中梯度最大的部分
梯度常常会受到图片中的噪声干扰,尤其是杂乱分布的椒盐噪声。所以为了准确实现边缘检测,往往需要先用滤波器处理图像,比较常用的滤波器就是高斯滤波(很准)和均值滤波(很快);随后还要对图像灰度邻域中强度显著变化的点进行增强;最后菜肴进行检测获取边缘点,经过增强的图像中往往有很多非边缘点梯度值变大了,这会导致检测错误,于是就需要对这些点进行取舍,一般来说使用二值化算法就可以得到不错的效果
常见的边缘检测算法包括
Canny算子:最常用,相对很优秀的边缘检测算法
Canny算子的核函数如下所示
$$
\left[ \begin{matrix}
-1 & 0 & +1 \
-2 & 0 & +2 \
-1 & 0 & +1 \
\end{matrix} \right]
$$
这个核矩阵用于处理x方向的梯度;它的转置矩阵用于检测y方向梯度需要二者结合才能很好地描述出图像的边缘信息
Sobel算子:这是一个离散微分算子,结合了高斯平滑和微分求导,是带方向性的边缘检测算法
这个算子相对Canny算子具有更好的抗噪性,不过计算量也会稍大一些
Laplacian算子:使用二阶偏导同时计算方向导数,内部调用了Sobel算子以处理图像梯度
本质上是对图像进行拉普拉斯变换后得到梯度最值
scharr滤波器:这是一个配额和Sobel算子的滤波器,通过使用这个滤波器,可以让Sobel算子更准确地提取出X、Y方向梯度
OpenCV中的函数已经在内部调用Sobel算子,不需要用户在外部使用
OpenCV给出的边缘检测函数如下
1 | void cv::Canny(cv::InputArray image, |
霍夫变换
霍夫变换可以从图像中识别出几何形状,可以从黑白图像中检测直线
霍夫变换在一个参数空间中通过计算累计结果的最大值得到一个符合该特定形状的集合作为其结果,这个算法对于数据不完全或噪声不敏感,并且可以扩展到任意形状物体的识别——一般是圆或椭圆。霍夫变换算法使用两个坐标空间之间的变换把相同形状的特征曲线映射到另一个坐标空间的一个点,形成峰值,从而将特定形状检测问题转化为统计峰值问题
OpenCV支持三种不同的霍夫线变换:
- 标准霍夫变换SHT
- 多尺度霍夫变换MSHT:SHT的多尺度改进版
- 累积概率霍夫变换PPHT:MSHT的改进版,可以在一定范围内进行霍夫变换,计算单独线段的方向和范围,从而减少计算量
霍夫变换使用极坐标而不是直角坐标来表示直线,从而让给定直线变成极坐标平面中曲线的交点,霍夫线变换追踪图像中每个点对应曲线间的焦点,如果交于一点的曲线数量超过阈值,说明这个交点代表的参数对应源图像中的一条直线
OpenCV给出了以下函数处理霍夫变换
1 | void cv::HoughLines(cv::InputArray image, |
需要注意:以上函数用于处理SHT和MSHT,同时需要定义一个矢量结构来存放得到的线段矢量
1 | vector<Vec4i> lines; |
使用下面的函数处理PPHT
1 | void cv::HoughLinesP(cv::InputArray image, |
除此之外还能使用推广的霍夫变换处理圆和椭圆图形,但是直接使用霍夫变换的话,累加平面会被三维的累加容器所替代,这样大量的内存会被消耗并且速度运算很慢。因此常常使用霍夫梯度法检测圆。首先对图像进行边缘检测,然后对图像中每个非零点使用Sobel函数计算x、y方向的Sobel一阶导数得到梯度。利用这些梯度就可以由斜率(一个指定的最小值到指定的最大值的距离)指定的直线上每个点累加。同时要标记边缘图像中每个非零像素的位置。从累加结果中选择候选的钟信,降序排列后依次考虑所有非零像素。将这些像素按照预期中心的距离排序,从最大半径的最小距离算起来支持像素的中心首先出现。再次对所有中心考虑所有非零像素的位置,重新排序后选择非零像素最支持的一条半径,这样就能得到一个圆了。
上面这段内容似乎不是什么人话(原书也用了一页来解释),这里简单梳理一下:
第一步根据每个点的模向量来找到圆心,这样三维的累加平面就转化为二维累加平面
第二步根据所有候选中心的边缘非零像素对其的支持程度来确定半径
一下就变得很简陋了(
边缘检测和求梯度、求斜率这三步都是为了求模向量,而后面两步迭代的考虑非零像素值则是为了对应每一点考虑它们的模向量。从候选中心的非边缘零像素对其的支持程度来确定半径就是最后两步的成果
这个算法中最大的问题在于需要使用Sobel导数——这会在输出中产生额外的噪声(实际使用时很可能导致图像中莫名其妙出现了飘着的圆圈),同时该算法的步骤会让他需要较高计算力才能实时运行
下面是OpenCV实现的函数
1 | void cv::HoughCircles(cv::InputArray image, |
同样需要定义一个矢量结构来存放得到的圆矢量
重映射
重映射是把一幅图像中某位置的像素放置到另一个图片指定位置的过程。由于源图像和目标图像像素坐标不一定一一对应,所以需要获得一些插值为非整数像素的坐标
重映射过程可以描述为
$$
g(x,y)=f(h(x,y))
$$
在OpenCV中使用remap()函数来实现基本重映射
1 | void cv::remap(cv::InputArray src, //源图像 |
其中插值方式可以选择如下算法:
- INTER_NEAREST:最近邻插值
- INTER_LINEAR:双线性插值
- INTER_CUBIC:双三次样条插值
- INTER_LANCZOS4:Lanczos插值
参数中其中map1如果被启用,且表示点(x,y),那么map2不会再被使用;如果map1使用了CV_16SC2、CV_32FC1、CV_32FC2类型的x值,那么它表示只对原图像的x值作变换,map2则会被认为只对原图像的y值作变换,此时两个参数都会被启用,一个变换x坐标,一个变换y坐标
使用例如下
1 | for( int j = 0; j < srcImage.rows;j++) |
得到下面的图像

仿射变换
仿射变换(Affine Transformation)又称仿射映射,是指在几何中一个向量空间进行了一次线性变换并接上一个平移,变换为另一个向量空间的过程。仿射变换就是平移及线性映射变换的复合——任何仿射变换都能使用矩阵乘法后加上一个向量的方式表示
$$
T=A \cdot \left[ \begin{matrix}
x \
y \
\end{matrix} \right]
- B
$$
上式中的xy列向量就表示了一个图像,T则是仿射变换后的图像
可以将如下三种变换转化成仿射变换:
- 平移(向量加)
- 旋转(线性变换)
- 缩放(线性变换)
OpenCV提供了两个函数来处理仿射变换
1 | cv::Mat cv::getAffineTransform(const cv::Point2f *src, const cv::Point2f *dst); |
上面的warpAffine函数需要配合getAffineTransform函数使用,getAffineTransform从dst-src两张图的映射关系中求得仿射变换矩阵,然后可以将矩阵传给warpAffine函数,让它进行变换
常见的使用格式如下:
1 | //设置两套向量及其对应关系,求出仿射变换矩阵 |
除了这个函数外,OpenCV还提供了专用于处理图像旋转的函数
1 | inline cv::Mat cv::getRotationMatrix2D(cv::Point2f center, //旋转中心 |
这个函数可以求得旋转变换矩阵
常用于以下情况:
1 | //计算绕图像中点顺时针旋转50度缩放因子为0.6的旋转矩阵 |
最后的处理还是要用到warpAffine()函数
