
MobileNet的原理与PyTorch实现
Mobilenet和ShuffleNet是目前应用比较广泛的两种轻量级卷积神经网络,轻量级网络参数少、计算量小、推理时间短,更适用于存储空间和功耗受限的边缘端和嵌入式平台。其中ShuffleNet是Face++在2017提出的轻量级网络,通过引入group和Channel Shuffle操作来让神经网络运算量大大减小。MobileNet是谷歌团队在同年提出的专注于移动端或者嵌入式设备中的轻量级CNN网络,提出了Inverted Residual Block结构,在此基础上能大大降低卷积层的消耗。二者的核心目标都是在尽可能减小准确率损失的条件下大量减少参数与运算量。到目前为止,MobileNet已经出现了三个版本,MobileNetv1、v2、v3;ShuffleNet也出现了两个版本:v1和v2。
由于MobileNetv2版本中也借鉴ShuffleNet使用了group操作,所以这里主要基于MobileNet介绍其结构和PyTorch官方实现(v2版本)
MobileNetv2已经被官方收录到PyTorch库中,可以直接调用;MobileNetv3还只有一个简单的个人实现。二者的GitHub仓库如下:
MobileNetv2
主要资料来自原论文(发布在CVPR2018上,也可以从官网看)、网络和个人整理
深度可分离的卷积
学术界一直在追求更高的性能,因此对于卷积网络的构建方法往往是“力大砖飞”,通过构建更深更复杂的网络以提高准确性,辅以各种训练trick和理论性能更高的算子,但工业界需要的一直是”更小更快“,这也是MobileNet的基本构建思想——将标准的卷积分解成深度卷积(DepthWise Conv)和点卷积(PointWise Conv)
传统的卷积直接将多个卷积核作用到多个特征图,得到多个输出特征图;MobileNet使用的深度可分离卷积(Depth-wise Separable Convolution)将这个过程拆分成两部分:depthwise卷积将与输入通道等量个滤波器对应作用到输入通道,pointwise卷积再使用与输出通道等量个1x1卷积核合并depthwise卷积的输出
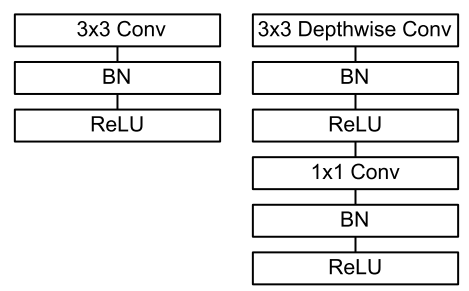
如上图,左边是传统的3x3卷积核卷积,右图是3x3卷积核深度可分离卷积
标准卷积的计算量为
输入特征图尺寸*输入特征图数量*输出特征图数量*卷积核尺寸
而深度可分离卷积的计算量为
dw卷积+pw卷积=dw输入特征图尺寸*dw输入特征图数量*dw卷积核尺寸+pw输入特征图数尺寸*pw输入特征图数量*输出特征图数量
二者作比可得到
深度可分离卷积/标准卷积=1/输出特征图数量+1/卷积核尺寸
对于3x3卷积核情况下, 可以得到8~9倍计算量的减少,需要付出的只是微小的准确率
ReLU6激活函数
MobileNetv2引入了ReLU6来取代ReLU,因为ReLU在低维度情况下会导致较大的特征损失,后面我们会提到MobileNet使用了先升维再降维的InvertedResidualBlock方法,因此ReLU不再适合作为降维后的激活函数
ReLU6函数实际上就是对ReLU作限幅,当输入数据大于6时,将其限制在6
下面是MobileNet中用到基本Conv-BN-ReLU6模块的构建
1 | class ConvBNReLU(nn.Sequential): |
这里CBR块会自行确定padding:当卷积核长宽大于3的情况下会加入padding
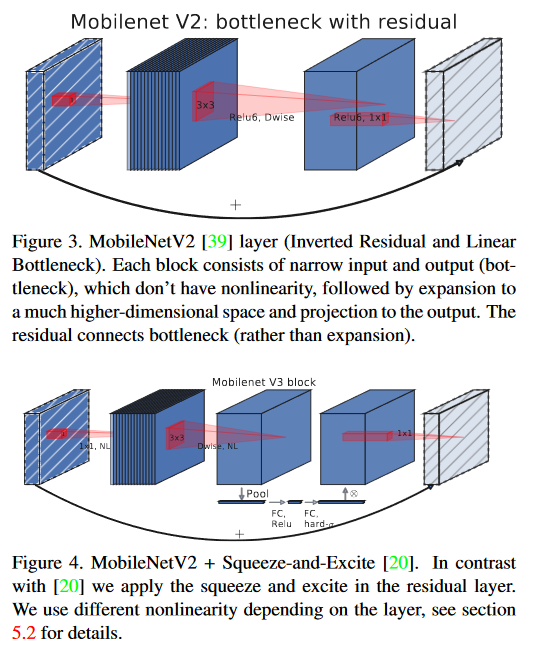
线性瓶颈和深度可分离卷积组成的倒残差结构
如下图所示,MobileNetv2汲取了ResNet的残差块思路,同时结合了深度可分离卷积。
输入数据首先分成两路,一个残差边直接连到输出进行加和,另一端数据先进入一个PW卷积,这个卷积的目的是升维——DW卷积没有改变通道数的能力,如果输入了很少的通道,那么DW卷积只能提取出低维特征,效果会很差,引入一个升维的PW卷积将数据维度提高到原来的t倍,这样后面的DW卷积就能提取出t*Cin维的特征
PW卷积和DW卷积后都加入了BN层和ReLU6层用来提高性能,随后数据会经过第二个PW卷积,完成降维回到和输入通道数相同的维度。特殊地,这层PW卷积后没有加入激活函数,因为作者认为激活函数存在线性瓶颈(Linear Bottleneck):在高维空间能够有效增加非线性,但在低维空间则会破坏特征。因此在降维后直接去掉ReLU,反而能获得更好的效果
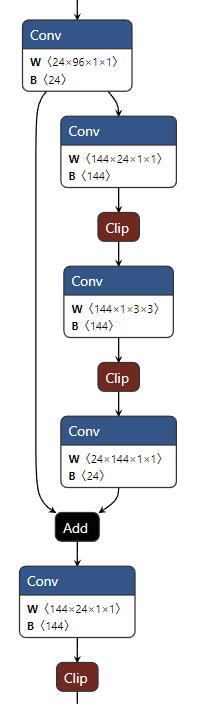
标准的ResNet残差块结构基于3x3卷积+残差边的形式,ResNet残差块是先降维卷积提取特征后再升维,MobileNetv2使用了相反的先升维提取特征后再降维,因此这种结构称为倒残差块InvertedResidualBlock
论文中表示”ResNet呈现沙漏形,InvertedResidualBlock则是纺锤形“,本质上这是对DW卷积在高维提取特征的适配
PyTorch的官方实现如下所示:
1 | class InvertedResidual(nn.Module): |
在倒残差块构建中,代码引入了expand_ratio参数,这个参数决定了隐藏层的维度和是否使用残差结构,在后面的网络主干结构中引入了一个总参数表,expand_ratio会被其中的参数t决定,暂且按下不表
网络主干
论文中的网络结构如下图所示:
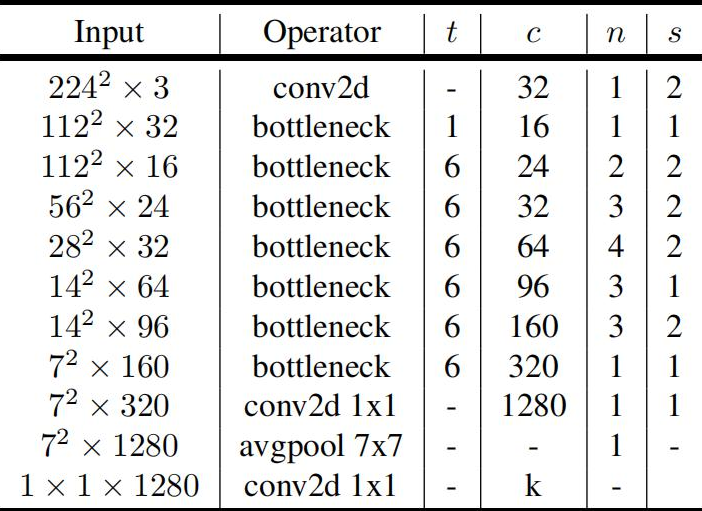
其中,
- t:扩展因子,对应上面倒残差块结构的
expand_ratio参数 - c:输出特征图深度(通道数)
- n:瓶颈层(也就是倒残差块)的重复次数
- s:卷积步长,只针对第一层卷积,与ResNet中引入的步长类似,用来改变特征图的尺寸
下面来整体介绍网络结构。
首先是决定网络输入层、输出层通道数的函数_make_divisible,函数根据输入通道数v和分割值divisor返回真正卷积的输入通道数
1 | def _make_divisible(v, divisor, min_value=None): |
网络主干引入了几个超参数:
- num_classes:输出种类,用于图像分类任务
- width_mult:位宽乘数,用于调整每层输入通道数
- inverted_residual_setting:指定倒残差块排布,需要更改网络结构才设置
- round_nearest:对每层通道数取整为该值的倍数
- block:指定使用的倒残差块类型,需要更改网络结构才设置
- norm_layer:指定BN层类型,需要更改网络结构才设置
1 | class MobileNetV2(nn.Module): |
这里着重强调一下倒残差块设置表
1 | inverted_residual_setting = [ |
第一列t是扩展因子,决定了每个倒残差块的升维系数,该表中除了第一个残差块(实际上就是一层卷积)外,都设置升维系数是6,也就是将维度升高6倍后提取特征再降维回原来的状态
第二列c输出通道数顾名思义,就是对应残差块输出的通道数目,代码中使用
1 | output_channel = _make_divisible(c * width_mult, round_nearest) |
构建,将其乘了系数width_mult(该程序中设置为1.0)并按round_nearest=8取整
我们能够发现如下规律
1 | inverted_residual_setting = [ |
主干网络呈升维趋势,每一层都比上一次提取更高维度的信息。
第三列n代表倒残差块的重复次数,官方实现没有重复超过4次,这是为了网络轻量级考虑,根据准确性和计算复杂度的侧重,可以适当修改重复次数
第四列s代表步长,MobileNet通过特定层中引入步长=2来改变输出特征图的大小
MobileNetv3
MobileNetv1提出了DW-PW结构的深度可分离卷积,并引入了ReLU6结构;MobileNetv2在其基础上借鉴ResNet构建Bottleneck,并使用PW-DW-PW实现了升维-特征提取-降维的倒残差块结构,并根据线性瓶颈理论去掉了倒残差块最后的ReLU来提高效率;MobileNetv3则在v2基础上使用两种AutoML技术——MnasNet和NetAdapt让网络效率进一步提升
MobileNetv3提供了两个版本,分别为MobileNetv3-l(large)以及MobileNetv3-s(small),二者的区别在于网络主干bottleneck的个数,small为11个,large为15个,网络结构如下图所示
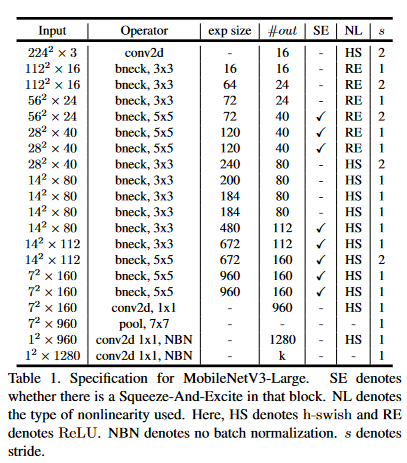
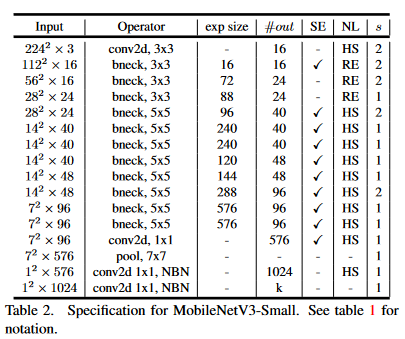
v3版本其实算是“非人造”的CNN,因为其中的主干网络构建依赖于AutoML技术,很多参数都是通过另外的网络生成的,只有一些神经网络难以优化的部分被人为修改。这里主要介绍对应的trick和基本技术理念
下面详细介绍MobileNetv3的实现
AutoML
谷歌在2019年提出了MnasNet——一个优于MobileNet的网络,但特别的是这个网络是使用强化学习神经结构搜索(NAS)构建的。团队将网络结构设计问题描述为一个考虑CNN模型精度和推理实时性的多目标优化问题,使用架构搜索和强化学习以找到模型。
模型产生过程就是设置一个目标,控制网络遍历可能的组合,生成一个CNN,把这个CNN在ImageNet上跑几轮以后转换成TFLite,在到移动端用单核CPU测试延迟,分别得到准确度和延迟,再反馈给控制网络。消耗大量算力以后就搞出来帕累托最优的模型了
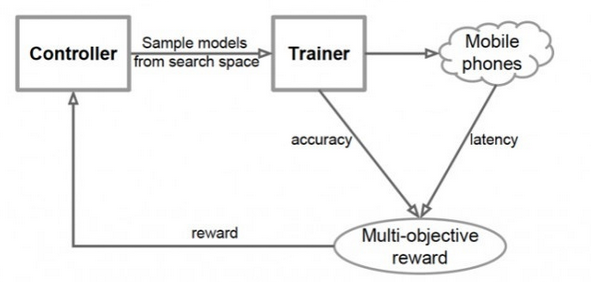
MobileNetv3正是在NAS技术构建出的MnasNet上实现的
hswish和hsigmoid激活函数
MobileNetv3采用hswish函数作为激活函数,从而大大优化网络的非线性表达
常规swish函数采用x * sigmoid(x)实现,但由于sigmoid过于费时,作者采用ReLU6作为替代,于是有
$$
hswish(x)=x \times ReLU6(x+3)/6
$$
同样更换的还有sigmoid函数:
$$
hsigmoid(x)=ReLU6(x+3)/6
$$
作者对比了hswish和ReLU,发现hswish在高维度的特征提取中效果更好,根据MobileNetv2的经验就只在高维度的层后使用hswish——模型每个倒残差块中第一个PW卷积层后使用常规ReLU函数,而在之后的DW卷积层后使用hswish函数。
在实际部署中,往往采用乘0.16667完成除以6的操作,x+3和ReLU6会被融合到卷积层权重和偏置内
1 | class hswish(nn.Module): |
SE通道注意力模块
MobileNetv3在结构中加入了SE-Net,将其放在dw卷积之后。因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样既提高了精度,同时还没有增加时间消耗。
这个网络的核心思想是在基础网络之上使用另一个新的神经网络,让这个网络通过学习来自动获取到特征图每个通道的重要程度,然后依照这一结果给每个特征图赋一个权重值,这样能让神经网络重点关注有用的特征并抑制对当前任务用处不大的特征,这就是经典的SE注意力机制
SE注意力机制的实现步骤如下:
- Squeeze:通过全局平均池化将每个通道的二位特征压缩为一个数
- Excitation:为每个特征通道生成一个权重值,经过两个全连接层构建通道间相关性
- Scale:将得到的权重归一化并加权到每个通道的特征上
也就是说SE注意力机制结构为:平均池化-全连接-全连接-矩阵乘法
于是得到改进的倒残差块变成了这样的结构:
具体代码实现如下:
1 | class SeModule(nn.Module): |
里面的两层CBR块就是为了替代全连接层的功能,可以尽可能减小参数量
得到的倒残差结构如下所示:
其中nolinear表示采用的非线性层类型,semodule表示采用的SE模块类型
1 | class Block(nn.Module): |
高效输出网络
MobileNetv2在平均池化层前加入了一个1x1的pw卷积,用于提高特征图维度,但这带来了一定计算量,MobileNetv3优化了这个结构,先使用平均池化将特征图从7x7缩小到1x1,再使用pw卷积升维,这样减小了7x7=49倍的计算量。同时v3直接去掉了前面一层倒残差块,测试发现两种结构并没有显著的性能差异。新老结构对比如下:
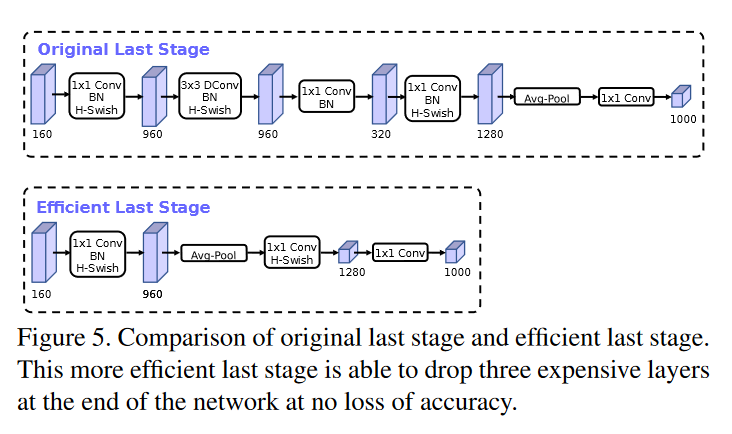
这个结构显然更符合MobileNet轻量化的预期
NetAdapt算法优化
NetAdapt算法也是基于强化学习的网络优化算法,专门用于对各个模块确定之后的网络层微调每一层的卷积核数量,也被称为层级搜索(Layer-wise Search)
MobileNetv3的主干网络参数就是通过该算法优化的
很显然使用这个算法会大大增加网络构建过程中的计算量,不过在网络构建以后就不需要再考虑它了
网络主干
这里以MobileNetv3-l为例,s模型是与之类似的,只不过网络层数变少了,参数也有所不同
GitHub上的实现没有采用和v2一样的设置表,而是简单的逐块设置bneck。代码相对简单,分成了输入、bneck、输出三大部分。
输入部分就是一个用来hswish激活函数的3x3卷积核,步长=2的卷积块。输出部分和上面提到的改进一样
重点的残差块参数从左往右依次是:卷积核大小、输入通道数、扩展因子(升维系数)、输出通道数、非线性层种类、是否采用SE注意力模块、步长
需要注意:网络的总体参数基于MnasNet修改,根据NetAdapt算法优化决定,因此可以说达到了相对完美的程度
1 | class MobileNetV3_Large(nn.Module): |
